Előrejelzések verifikációja II.
A verifikációs témakör folytatásaként ebben az írásban a folytonos-determinisztikus előrejelzések és a valószínűségi előrejelzések verifikációjáról emlékezek meg. Ahogyan az első cikkben, itt is csak a legegyszerűbb és legismertebb módszereket sorolom fel.
1. Folytonos-determinisztikus előrejelzés
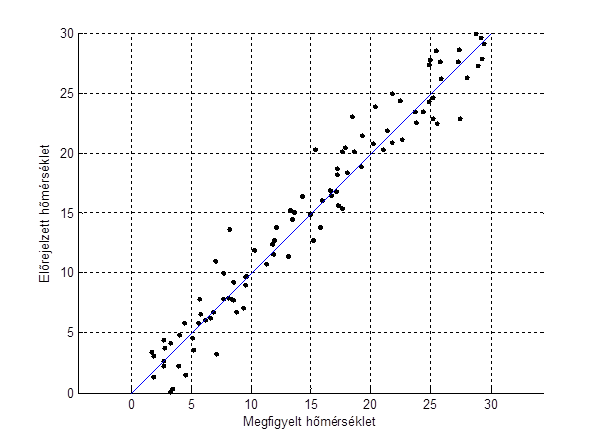
A folytonos változók előrejelzésére jó példa a hőmérséklet-előrejelzés. A legegyszerűbb ábrázolási metódus az ún. scatter-plot, ahol két dimenzióban felrakjuk az összetartozó előrejelzés-megfigyelés pontokat.

Az ideális előrejelzés az lenne, ha az összes pont a kék, átlós egyenesen helyezkedne el.
Ha számszerűsíteni szeretnénk az előrejelzés hibáját, akkor valahogyan ettől az egyenestől való eltérést kell figyelembe vennünk. Több mérőszám létezik ennek leírására:
- Átlagos hiba (mean error/bias):
 [1]
[1]
ahol fi az i. előrejelzett érték, az oi pedig i. megfigyelt érték.
Értéktartomány: -∞..+∞
Tökéletes előrejelzés esetén értéke: 0
Ez a legegyszerűbb mérőszám, viszont több hátránya is van: Nem méri a hiba abszolút értékét, és az előrejelzés-megfigyelés közötti megfelelést: a nullát úgy is el lehet érni, hogy pozitív-negatív irányban kikompenzálják egymást a hibák.
- Átlagos abszolút hiba (mean absolute error):
 [2]
[2]
Értéktartomány: 0..+∞
Tökéletes előrejelzés esetén értéke: 0
Az előzőhöz képest itt a hibák abszolút értékét vesszük. Hátránya, hogy nem veszi figyelembe a hiba irányát.
- Átlagos négyzetes hiba (mean squared error):
 [3]
[3]
Ez sem veszi figyelembe a hiba irányát, és a nagy eltérésekre érzékenyebb a négyzetre emelés miatt.
- Átlagos négyzetes hiba gyöke (root mean squared error):
 [4]
[4]
Ez az előző kifejezés (MSE) négyzetgyökeként értelmezhető, és az eredeti mennyiséggel (azaz a megfigyelt változóval) azonos mértékegységgel rendelkezik.
- Korrelációs együttható
Az érthetőség és az egyszerűbb felírás érdekében érdemes először bevezetni az átlagot és a szórást. Az előrejelzések és megfigyelések átlaga:


A szórások definíciója előrejelzésre és megfigyelésre:
 [5]
[5]
 [6]
[6]
Ezekkel a mennyiségekkel a korrelációs együttható kifejezése:
 [7]
[7]
Értéktartomány: -1..+1
Tökéletes előrejelzés esetén értéke: 1
Ez a szám azt mondja meg, hogy a pontokat 2 dimenzióban felrajzolva mennyire vagyunk közel egy egyeneshez (nem feltétlenül a 45 fokos "tökéletes" egyeneshez!). Ennek következtében az eltolásra nem érzékeny (pl. ha az előrejelzett értékekhez hozzáadunk 10-et, ugyanazt az értéket kapjuk). Emellett érzékeny a kiugró adatokra.
Megjegyzés: Ezt a képletet bináris előrejelzésekre alkalmazva az ott tárgyalt MCC-t (Matthews correlation coefficient) kapjuk.
- Lineáris regresszió meredeksége: Ez annak az egyenesnek a meredeksége, amit a ponthalmazra ráilleszthetünk.
 [8]
[8]
Az 1 jelenti a tökéletes előrejelzést, azaz egy 45 fokos egyenest. Viszont ez az egyenes nem feltétlenül egyezik meg az y=x egyenessel. Ebben a képletben az s0 a megfigyelt értékek szórása, sf az előrejelzések szórása, és r a korrelációs együttható. Ezen mennyiségek a fentiekben vannak definiálva ([5], [6], [7]).
- Skill-score: Természetesen ez a fajta általánosított mérőszám folytonos előrejelzésekre is alkalmazható, nem csak binárisokra.
 [9]
[9]
Itt az Aref a referencia előrejelzés pontszámát jelöli. A referencia előrejelzés általában a klimatológiát vagy a perzisztencia előrejelzést jelenti. Az előbbinek két fajtája van, az egyiknél az adatok átlagát használjuk fel, a másiknál pedig egy más forrásból vett idősorok adatának átlagát vesszük (pl. adott napon, hónapban, attől függően, milyen időpontra vonatkozik az előrejelzés). Perzisztencia előrejelzés esetén az időjárás utolsó észlelt állapototát vetítjük ki a jövőre, és azt jelezzük előre, változatlanságot feltételezve.
Az Aperfect a tökéletes előrejelzés pontszámát jelenti.
Tekintsünk a fenti folytonos mérőszámok jelentésének megvilágítására egy példát. A verifikálandó adathalmaz most az egyszerűség kedvéért 5 darab előrejelzés-megfigyelés párból áll.
| Előrejelzés | Megfigyelés | Hiba |
| 3 | 4 | -1 |
| 4 | 7 | -3 |
| 7 | 7 | 0 |
| 4 | 3 | 1 |
| 2 | 2 | 0 |
A hiba előjeles definíciója itt az előrejelzés mínusz a megfigyelés.
Az adatokat 2 dimenziós ábrán ábrázolva:

A fenti hibákból egyszerűen kiszámolhatóak a következő indexek:
- Átlagos hiba (ME) : -0.6
- Átlagos abszolút hiba (MAE): 1
- Átlagos négyzetes hiba (MSE): 2.2
- Átlagos négyzetes hiba gyöke (RMSE): 1.4832
- Előrejelzések átlaga: 4
- Megfigyelések átlaga: 4.6
A további, tárgyalt mérőszámok értékei:
- Előrejelzések szórása: 1.6733
- Megfigyelések szórása: 2.0591
- Korrelációs együttható: 0.7546
- Lineáris regresszió meredeksége: 0.9286
Példa a skill-scorehez (SS): Ha az átlagos abszolút hibát (MAE) választjuk ki, és referencia értékének pl. a 0.5 fokot állítjuk be, akkor SS értéke a képletbe behelyettesítve -1, mivel a tökéletes előrejelzéshez nulla MAE érték tartozik. A -1-es érték azt jelenti, hogy a referenciánál 100%-kal rosszabb az előrejelzésünk.
Az MSE dekompozíciója
Az átlagos négyzetes hibának (MSE) többféle dekompozíciója létezik. Ezek azt a célt szolgálják, hogy meg tudjuk vizsgálni, a hiba milyen komponensekből tevődik össze.
Egyik lehetséges felbontás, ami az átlagokat, szórásokat és a korrelációs együtthatót is felhasználja:
 [10]
[10]
A skill-score-t alkalmazva az MSE-re:
 [11]
[11]
Amennyiben a referencia előrejelzést a megfigyelések átlagának választjuk:

Ha MSE-re behelyettesítjük a fenti dekompozíciót:

Ezt átalakítva a végleges alakja:
 [12]
[12]
Ebben három tagot lehet megkülönböztetni:
- lineáris asszociáció/megfelelés: azt fejezi ki, hogy a pontok mennyire esnek egy egyenesre. Ha 1, akkor az összes pont egy egyenesre esik. Ez a tag az ún. maximálisan megmagyarázott variancia.
- feltételes torzítás: a ponthalmaztra illesztett egyenesnek a 45 fokos meredekségtől való eltérését bünteti, ami azt jelenti, hogy ideális esetben nulla az értéke, egyébként pedig egy ettől eltérő pozitív értékkel rendelkezik.
- abszolút torzítás: az átlagos hibát (offszet) bünteti, ami annak a mértéke, hogy átlagos értelemben véve mennyivel vannak az előrejelzések és a megfigyelések egymástól eltolódva ([1] képlet).
Ha az SS mindhárom tagját megvizsgáljuk különböző előrejelzések összehasonlítása során, akkor pontosabb képet kaphatunk.
Példa: a következő két esetben a lineáris asszociáció értéke 1, azaz egy egyenes mentén fekszenek az adatok. Van viszont a bal oldali esetben abszolút torzítás (eltolás), a jobb oldali esetben pedig feltételes torzítás.


Egyéb mérőszámok
- Anomália korreláció: A korrelációs együttható egy olyan módosításának felel meg, amikor az átlagos előrejelzés és az átlagos megfigyelés helyére a klimatológiai átlagot (c) helyettesítjük be:
 [13]
[13]
Értéktartomány: -1..+1
Tökéletes előrejelzés esetén értéke: 1
Sok helyen használják numerikus előrejelző modellek verifikációjához.
A folytonos előrejelzéseknél léteznek olyan mérőszámok is, amelyek az előrejelzések és megfigyelések eloszlásainak különbségéből dolgoznak (pl. Linear error in probability space vagy LEPS). Ezeket itt nem tárgyalom.
2. Valószínűségi előrejelzés
Először is célszerű definiálni a valószínűségi eloszlásokat (ez a definíció csak diszkrét eseményekre vonatkozik, a folytonos változattal itt nem foglalkozom):
Valószínűségi előrejelzésről akkor beszélünk, amikor egy esemény bekövetkezéséhez egy 0 és 1 közötti számot (vagy 0-100%) rendelünk hozzá, és ez az adott esemény valószínűségét reprezentálja.
Egy valószínűségi eloszlás abból áll, hogy az összes lehetséges kimenetelhez hozzárendelünk egy valószínűség értéket, olyan módon, hogy ezen számok összege 1.
A valószínűségi előrejelzés verifikációját abban az esetben érdemes elvégezni, ha viszonylag sok előrejelzés-megfigyelés pár áll a rendelkezésre. Például egyetlen bekövetkezett eseményből, amit 80%-al jeleztünk előre - nem sok mindent lehet kijelenteni az előrejelzés jóságáról.
Kategóriákba sorolás: A valószínűségek bármilyen értéket felvehetnek 0 és 1 között. Verifikáció szempontjából viszont érdemes ezeket csoportosítani (például: 0-20%, 20-40%, 40-60%, 60-80%, 80-100%). Ezzel a kiértékelés sokkal átláthatóbbá, értelmezhetőbbé válik. Lehetséges már az előrejelzést is úgy módosítani, hogy rögtön ezeket a kategóriákat jelezzük előre (pl. egy 76.343%-os érték bemondása helyett a 60-80%-os kategóriába soroljuk be).
A kiértékelésnél a tartományok középső értékei fognak számítani, ezért sokszor a kategóriákat is egyből ezen számokkal címkézik meg (ebben a példában: 10%, 30%, 50%, 70%, 90%). Megjegyzendő, hogy ezzel a lépéssel természetesen információveszteség keletkezik, viszont cserébe egyszerűsítjük a kiértékelés folyamatát.
A valószínűségi előrejelzés tulajdonságai
- pontosság (accuracy): Ez annak a mértéke, hogy az előrejelzés és a megfigyelés mennyire egyezik meg. Ez az ún. Brier-scoreval mérhető.
- skill: Ez azt jelenti, hogy egy referencia előrejelzéshez (pl. klimatológia) képest mennyivel jobb az adott előrejelzés
- megbízhatóság (reliability): az előrejelzett valószínűségek közel vannak az esemény előfordulási gyakoriságához. Például, ha a kiértékelésnél az "50%-os valószínűség" címkéjű kategóriát választjuk ki, és ebben a csoportban az előfordulási gyakoriság is pontosan 50%, akkor ebből a szempontból tökéletesnek mondható az előrejelzésünk, legalábbis erre a kategóriára nézve.
- felbontás (resolution): különböző előrejelzett valószínűségekhez különböző esemény-gyakoriságok tartoznak. Pl. ha a 30%-os és a 70%-os valószínűségi kategóriában is közel ugyanakkora előfordulási gyakoriságot kapunk, az nem utal egy használható előrejelzésre - tehát nincs értelme megkülönböztetni a kategóriákat.
- élesség (sharpness): Arról ad információt, hogy az előrejelzés mennyire tér el a 0 és 1 szélsőértékektől. Ha mindig 0-át vagy 1-et jelzünk előre, akkor vagyunk a "legélesebbek", vagy más szóval a legbiztosabbak a kimenetelt illetően. Az előrejelzési valószínűségek varianciájával mérhető.
- bizonytalanság (uncertainty): Ez az élességhez hasonló dolog, de itt az észlelést vizsgáljuk, hogy mennyire bizonytalan az adott esemény - a legbizonytalanabb eset az, ha a 50%-ban fordul elő. Az események varianciájával mérhető.
- diszkrimináció (discrimination): Mennyire lehet elkülöníteni az bekövetkezett eseményeket a nem bekövetkezett eseményektől úgy, hogy különböző előrejelzési kategóriát adunk rájuk.
2.1 Bináris előrejelzés
Egy bináris esemény előrejelzéséhez tartozó valószínűségi eloszlás mindössze egyetlen számmal leírható, hiszen ha "x" a bekövetkezés valószínűsége, akkor a nem bekövetkezés valószínűsége (a komplementer esemény törvénye miatt) "1-x".
A megfigyelés ebben az esetben csak két értéket vehet fel: 0 vagy 1 (nem vagy igen).
Brier-score
A leggyakrabban alkalmazott mérőszám. Megegyezik a folytonos előrejelzéseknél leírt MSE képletével (Mean Squared Error [3]), a különbség mindössze az, hogy az előrejelzés (f) egy 0 és 1 közötti szám, a megfigyelés (o) pedig csak 0 vagy 1 lehet.
 [14]
[14]
A Brier-scorenak - hasonlóan az MSE-hez - többféle felbontása létezik. A legismertebb a megbízhatóság-felbontás-bizonytalanság felbontás. Ha az előrejelzések kategóriákba vanak sorolva, akkor felírható a következő alakban:
 [15]
[15]
Magyarázat:
M az előrejelzési kategóriák száma,  a j. kategóriába eső előrejelzések előfordulási aránya,
a j. kategóriába eső előrejelzések előfordulási aránya,  az események előfordulási gyakorisága a j. kategóriában, p az esemény előfordulási aránya a teljes adathalmazon. Az
az események előfordulási gyakorisága a j. kategóriában, p az esemény előfordulási aránya a teljes adathalmazon. Az  az adott kategóriában előrejelzett (konstans) valószínűség.
az adott kategóriában előrejelzett (konstans) valószínűség.
A tagok értelmezése sorrendben:
- megbízhatóság (reliability): a kategóriákban előrejelzett valószínűségek mennyire térnek el a ténylegesen bekövetkezett gyakoriságoktól - mennyire jók az előrejelzett valószínűség értékek?
- felbontás (resolution): a kategóriákban tapasztalt gyakoriságok mennyire térnek el az átlagos gyakoriságtól (klimatológiától) - mennyire bontottuk fel jól kategóriákra az előrejelzést?
- bizonytalanság (uncertainty): Ez egyenlő az események varianciájával, azaz mennyire bizonytalan magának az eseménynek a bekövetkezése. Ez a tag nem függ az előrejelzéstől, csak az esemény előfordulásától/klimatológiájától.
Értéktartomány: 0..+1
Tökéletes előrejelzés esetén értéke: 0
A BS egyik hátránya, hogy ritka esemény esetén könnyű jó értékeket elérni. Az utolsó tag miatt különböző adathalmazokon nincs értelme összehasonlítani a Brier-score-kat.
Brier skill score
A Brier-scoréből is lehet gyártani skill-score-t, a már megismert módszerrel:
 [16]
[16]
Ha referenciának azt választjuk, amikor csak egyetlen előrejelzési kategóriát használunk, aminek p a valószínűsége, akkor a referencia Brier-score tagjai közül
 és
és  is 0 lesz, és csak az utolsó "UNC" tag marad, ami viszont ugyanaz a referencia és a verifikált előrejelzésünk esetén. Ezért a fenti képlet leegyszerűsödik:
is 0 lesz, és csak az utolsó "UNC" tag marad, ami viszont ugyanaz a referencia és a verifikált előrejelzésünk esetén. Ezért a fenti képlet leegyszerűsödik:
 [17]
[17]
Tökéletes előrejelzés esetén értéke: 1, a 0 jelenti azt, hogy nincs javulás a referencia előrejelzéshez képest. Hátránya, hogy kis adathalmaz esetén instabil értékeket ad, ritka eseménynél esetén (amikor p és UNC nulla közeli) sok adat kell, hogy megbízható értéket adjon.
Megbízhatósági diagram (reliability diagram)
Ez egy grafikus módszer, amivel egyszerűen lehet szemléltetni az előrejelzés megbízhatóságát, azaz a tényleges gyakoriság mennyire tér el az előrejelzettől. Emellett a Brier-score egyes tagjait is lehet vele vizuálisan szemléltetni.

A vízszintes tengelyen az előrejelzett valószínűség, a függőleges tengelyen pedig az adott kategóriában az esemény előfordulási gyakorisága. Annál jobb az előrejelzés, minél jobban a főátló közelében van a kék görbe (ha a főátlón vagyunk, akkor REL=0). Amennyiben a kék görbe az átló alatt fut, akkor túlbecsültük, ha felette, akkor pedig alábecsültük az adott valószínűséget.
A vízszintes szaggatott vonal jelenti a klimatológiai előrejelzést, azaz ha mindig az esemény átlagos előfordulását jeleznénk előre (ez ebben a példában kb. 11%) - erre mondjuk, hogy nincs felbontása az előrejelzésnek (ezen a vonalon RES=0).
A főátló és a vízszintes között félúton elhelyezkedő szaggatott vonal pedig a BSS=0 értéket jelenti (REL=RES), e fölött BSS pozitív, alatta pedig negatív.
A megbízhatósági diagrammal rendszerint együtt szokták ábrázolni az úgynevezett élességi diagramot (sharpness diagram):

5. ábra
Diszkrimináció, ROC görbe
A megbízhatósági diagram az adatokat előrejelzési kategóriák szerint vizsgálja meg. Ezzel szemben egy másik megközelítés az, hogy kettébontjuk az adatokat aszerint, hogy az esemény bekövetkezett, vagy sem. Erre egyik eszköz az ún. likelihood-diagram:

6. ábra
Ez hasonlít az élességi diagramra, viszont itt az egyes kategóriákban ketté vannak bontva az előrejelzések aszerint, hogy bekövetkezett-e vagy sem az adott esemény.
Tegyük fel, hogy a fenti adatok egy csapadék-előrejelzésre vonatkoznak, és egy tetőfedő megkérdezi tőlünk: "Ez rendben van, de milyen valószínűségi értéket javasolnak, ami felett nem érdemes elkezdeni a munkát."
Az ilyen jellegű kérdésre a ROC görbe adhat választ, amit a determinisztikus előrejelzéseknél már megemlítettem. Tulajdonképpen arról van szó, hogy M kategória esetén M-1 darab determinisztikus előrejelzéssé konvertáljuk a fenti valószínűségi előrejelzést a következő módon:
- "elvágjuk" a fenti ábrát két kategória között (10%, 20%, 30%-es stb. küszöbértékek mentén)
- meghatározzuk a hozzátartozó kontingencia-táblázatot (hit, miss, false alarm, correct negatives)
- kiszámoljuk a true positive rate (TPR) és false positive rate (FPR) értékeket, és ábrázoljuk egy diagramon. (a TPR és FPR részletes definícióit lásd az Előrejelzések verifikációja I. c. anyagban)
Az így kapott ábrát ROC görbének nevezzük:

7. ábra
Így meg tudjuk állapítani az egyes valószínűségi küszöbértékekhez tartozó a TPR és FPR értékeket.
Kiválaszthatunk egyéb mérőszámot is (pl. True Skill Statistic, Matthew's Correlation Coefficient), amelyhez aztán meghatározhatjuk az optimális döntési küszöbértéket is - az összes ponthoz tartozó érték kiszámolása után.
Mint mérőszám, felhasználhatjuk a költség képletét is, amely a TPR és FPR értékekkel is felírható (a költség részletes kifejtését lásd az Előrejelzések verifikációja I. c. anyagban):

ROC görbe alatti terület
Amennyiben nem egy optimális küszöbértékre vagyunk kíváncsiak, hanem arra, hogy az adott valószínűségi előrejelzés potenciálisan milyen diszkriminációs képességgel rendelkezik, akkor e célból definiálhatjuk a ROC görbe alatti területet (az alábbi ábrán türkiz színnel van jelölve).

8. ábra
Általában kb. 0.7 felett tekintjük az előrejelzést gyakorlatban is hasznosnak. Összehasonlításképpen, a fenti ábrán ez a terület 0.874.
Meg kell említeni, hogy ritka események esetén a TPR-FPR pontok az ábra bal felére koncentrálódnak. Ha kevés minta áll rendelkezésre, akkor előfordulhat az is, hogy bizonyos értéknél nagyobb küszöbértékeket már nem tudunk ábrázolni - a magas valószínűségi kategóriákban nem lesz elég esetünk, hogy megállapítsuk ezeket az arányokat.
Fontos, hogy a ROC görbe a megbízhatóságról nem mond semmit, tehát egy nem korrekt valószínűségeket tartalmazó előrejelzés is lehet diszkriminatív. Ezért a megbízhatósági diagram és a ROC görbe együtt alkalmazandó, mivel mindkettő más tulajdonságról ad információt.
2.2 Multikategóriás előrejelzés
Rank probability score
Amennyiben kettőnél több előrejelzési kategória van, és ezek sorrendbe állíthatóak (pl. nincs eső, kevés eső, sok eső), akkor az ún. rank probability score-t (RPS) szokás használni. Ez a Brier-score egy általánosításának tekinthető, két kategória esetén meg is egyezik azzal.
A következő módon számolható: Képezni kell az előrejelzés és a megfigyelés diszkrét eloszlásfüggvényeit. (Az eloszlásfüggvény definíciója egy x értéknél: mi a valószínűsége annak, hogy egy valószínűségi változó x-nél kisebb értéket vesz fel. Itt a "kisebb" alacsonyabb kategóriát jelent.)
 [18]
[18]
Az f értékei a kategória valószínűségek (0 és 1 között), az o értékei pedig vagy 0 vagy 1 értéket vehetnek fel (indikátor változó - melyik kategória történt meg).
Ezt felhasználva a képlet, egyetlen esetre:
 [19]
[19]
ahol K a kategóriák száma.
Egy példa az értelmezés megkönnyítéséhez: Tegyük fel, hogy 5 kategóriát jelzük előre a következő valószínűségekkel: 30%, 40%, 20%, 10%, 0%. A bekövetkezett esemény a 2. kategóriába esik. Ezt egy ábrán szemléltetve:


9. ábra
Bal oldalt a valószínűségi eloszlások, jobb oldalt pedig az eloszlásfüggvények láthatóak az egyes kategóriákhoz tartozóan. Az utóbbiak különbségét kell képezni (piros oszlopok), és ezek négyzete emelt összege adja az RPS-t.
Az utolsó lépésben az összes esetre kiszámolt érték átlagát kell venni, így kapjuk a teljes verifikációs adathalmazra értelmezett RPS-t.
Értéktartománya megegyezik a Brier-score esetén látottakkal (0..+1) és tökéletes előrejelzés esetén értéke: 0. Akkor ad jó értéket, ha az előrejelzett valószínűség-eloszlás viszonylag éles, és a megtörtént esemény magas előrejelzett valószínűségű kategóriába esik.
Rank probability skill score
Ugyanúgy, ahogy a Brier-score esetén, itt is definiálható egy skill-score:
 [20]
[20]
ahol  egy referencia előrejelzés RPS értéke. Értkétartományára ugyanaz mondható el, mint a BSS-nél.
egy referencia előrejelzés RPS értéke. Értkétartományára ugyanaz mondható el, mint a BSS-nél.
2.3 Folytonos előrejelzés
Continuous rank probability score
Az RPS-nek létezik egy kiterjesztése folytonos előrejelzésekre is, ez a CRPS:
 [21]
[21]
Itt az összegzés helyett integrál található, és diszkrét eloszlásfüggvények helyett folytonosak szerepelnek:  az előrejelzés,
az előrejelzés,  a megfigyelések eloszlásfüggvénye.
a megfigyelések eloszlásfüggvénye.
Példa a szemléltetéshez: Ha az észlelés az x=3 pontban történt, az előrejelzés pedig egy 1 középpontú, 2 szórású Gauss görbe:


A CRPS a piros területnek feleltethető meg. Ez a terület akkor kicsi, ha az előrejelzés szórása kicsi (éles előrejelzés), és a középpontja pedig közel van a megfigyeléshez (pontos előrejelzés).
A teljes adathalmazra vett CRPS-t az összes esetre számolt átlaggal kapjuk meg.
A CRPS egy érdekes tulajdonsága, hogy amennyiben az előrejelzés determinisztikus, akkor megegyezik a folytonos előrejelzéseknél tárgyalt MAE mérőszámmal (hiszen akkor a fenti integrál egy téglalap területébe megy át, aminek a magassága 1 egység hosszú, a másik oldalának hossza pedig az előrejelzés és a megfigyelés különbségének abszolút értéke).
Ez azért előnyös, mert így könnyen összehasonlíthatóvá válik egy determinisztikus és egy valószínűségi előrejelzés.
Rank histogram
Ez inkább egy diagnosztikai módszernek tekinthető, mint verifikációs módszernek. Ensemble előrejelzések esetén használják.
Az ensemble tagjainak összességét fel lehet fogni valószínűségi eloszlásként is, vagy annak jó közelítéseként.
Feltételezik, hogy az ensemble egyes tagjai egyenlő valószínűségekkel következnek be, ezért az egyes ensemble tagok közé nagyjából egyenlő számú megfigyelés kell essen.
Ha az ensemble N tagból áll, a tartományt felosztják N+1 részre (az ensemble elemei a tartományhatárok), és megnézik, hogy a megfigyelés melyik tartományba esik (rang meghatározás). Amennyiben az összes esetet nézve, az összes ranghoz nagyjából azonos számú megfigyelés van hozzárendelve, akkor azt lehet mondani, hogy az ensemble jól reprezentálja az adott változó megfigyelt eloszlását.
| Csatolmány | Méret |
|---|---|
| image001.png | 9.75 kB |
| image002.png | 1.27 kB |
| image003.png | 1.22 kB |
| image004.png | 1.27 kB |
| image005.png | 1.41 kB |
| image006.png | 866 byte |
| image007.png | 826 byte |
| image008.png | 1.15 kB |
| image009.png | 1.1 kB |
| image010.png | 1.47 kB |
| image011.png | 651 byte |
| image012.png | 967 byte |
| image013.png | 9.3 kB |
| image014.png | 1.45 kB |
| image015.png | 1.21 kB |
| image016.png | 1.42 kB |
| image017.png | 1.42 kB |
| image018.png | 1.55 kB |
| image019.png | 3.89 kB |
| image020.png | 3.89 kB |
| image021.png | 2.47 kB |
| image022.png | 1.13 kB |
| image023.png | 2.18 kB |
| image024.png | 375 byte |
| image025.png | 344 byte |
| image026.png | 364 byte |
| image027.png | 994 byte |
| image028.png | 567 byte |
| image029.png | 596 byte |
| image030.png | 1.12 kB |
| image031.png | 11.37 kB |
| image032.png | 6.58 kB |
| image033.png | 8.96 kB |
| image034.png | 10.04 kB |
| image035.png | 1015 byte |
| image036.png | 7.75 kB |
| image037.png | 1.26 kB |
| image038.png | 1.47 kB |
| image039.png | 3.19 kB |
| image040.png | 3.55 kB |
| image041.png | 847 byte |
| image042.png | 583 byte |
| image043.png | 1.36 kB |
| image044.png | 534 byte |
| image045.png | 503 byte |
| image046.png | 2.99 kB |
| image047.png | 3.22 kB |
- A hozzászóláshoz belépés szükséges

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
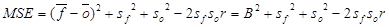{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
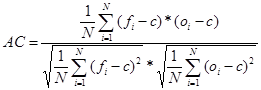{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}